| 出願番号 |
特願2022-029327 |
| 出願日 |
2022/2/28 |
| 出願人 |
国立研究開発法人情報通信研究機構 |
| 公開番号 |
特開2023-125311 |
| 公開日 |
2023/9/7 |
| 発明の名称 |
言語モデル学習装置 |
| 技術分野 |
情報・通信 |
| 機能 |
制御・ソフトウェア |
| 適用製品 |
音声認識における誤りに頑健な言語モデルを学習するための言語モデル学習装置、対話装置及び学習済言語モデル |
| 目的 |
音声合成及び音声認識の性能から独立しており、低い計算コストにより大規模言語モデルの学習が行える言語モデル学習装置、対話装置及び学習済言語モデルを提供する。 |
| 効果 |
低コストに学習が行え、高い精度の言語モデルが得られる。この言語モデルは音声認識器に依存しないため、使用される音声認識器がどのようなものであっても再学習の必要がない。さらに頑健な学習済言語モデルを実現できる。 |
技術概要
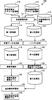 |
自然言語のテキストを変換して表音記号の記号列を出力するための変換手段と、
前記テキストと、前記変換手段により出力された前記記号列とを用いて、言語モデルの学習を行うための学習手段とを含む、言語モデル学習装置。 |
| 実施実績 |
【無】 |
| 許諾実績 |
【無】 |
| 特許権譲渡 |
【否】
|
| 特許権実施許諾 |
【可】
|
)