| 出願番号 |
特願2012-220426 |
| 出願日 |
2012/10/2 |
| 出願人 |
日本放送協会 |
| 公開番号 |
特開2014-074732 |
| 公開日 |
2014/4/24 |
| 登録番号 |
特許第6031316号 |
| 特許権者 |
日本放送協会 |
| 発明の名称 |
音声認識装置、誤り修正モデル学習方法、及びプログラム |
| 技術分野 |
情報・通信 |
| 機能 |
機械・部品の製造、制御・ソフトウェア |
| 適用製品 |
音声認識装置、誤り修正モデル学習方法、及びプログラム |
| 目的 |
音声認識に用いる誤り修正モデルを、コストを抑えながら学習することができる音声認識装置、誤り修正モデル学習方法、及びプログラムを提供する。 |
| 効果 |
音声を認識する際に用いる誤り修正モデルを、学習コストをおさえながら学習することができる。よって、さまざまな話題や話者についての誤り修正モデルを効率的に学習することが可能となる。 |
技術概要
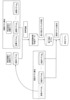 |
音声言語資源格納部21は、特定話者の発話の音声データと発話の正解文であるテキストデータとを格納し、統計モデル格納部31は、特定話者の音響モデルと話題別の言語モデルとを格納する。認識誤り生成部4は、音声言語資源格納部21が格納している音声データを、統計モデル格納部31が格納している特定話者の音響モデル及び特定話題の言語モデルを用いて音声認識し、認識誤りを含む音声認識結果を生成する。誤り修正モデル学習部5は、認識誤りを含む音声認識結果と、テキストデータが示す正解文とから統計的に認識誤りの傾向を分析し、誤り修正モデルを生成する。モデル統合部6は、誤り修正モデル学習部5が生成した誤り修正モデルと、統計モデル格納部31に格納されている複数の言語モデルとを統合した統合モデルを生成する。 |
| 実施実績 |
【無】 |
| 許諾実績 |
【無】 |
| 特許権譲渡 |
【否】
|
| 特許権実施許諾 |
【可】
|
)