| 出願番号 |
特願2007-067267 |
| 出願日 |
2007/3/15 |
| 出願人 |
日本放送協会 |
| 公開番号 |
特開2008-226162 |
| 公開日 |
2008/9/25 |
| 登録番号 |
特許第5100162号 |
| 特許権者 |
日本放送協会 |
| 発明の名称 |
テキスト分析装置及びテキスト分析プログラム |
| 技術分野 |
情報・通信 |
| 機能 |
機械・部品の製造、検査・検出 |
| 適用製品 |
テキスト分析装置及びテキスト分析プログラム |
| 目的 |
複数文から構成されるテキストデータから、定型的な表現を含む文章区間を自動抽出することが可能なテキスト分析装置及びテキスト分析プログラムを提供する。学習処理を効率的に短時間で行なえるテキスト分析装置及びテキスト分析プログラムを提供する。 |
| 効果 |
弱学習器サンプリング処理では、最適なものを選択する処理は行わず、事前に決定している有効性の事前分布に基づいて取り出すため、処理時間は少なくなる。つまり、テキストデータの必要な構造だけを効果的にサンプリングするために、学習時間は短くて済む。
また、選択された弱学習器の系列を一つでなく複数作成するため、頑健な判定器を作成できる。 |
技術概要
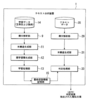 |
テキスト分析装置が、最終仮説情報を記憶する最終仮説情報記憶部と、学習データを構文解析した結果に基づき木構造を生成する第1木構造生成部と、生成された木構造から複数の部分木を抽出して弱学習器を生成する弱学習器生成部と、生成された複数の弱学習器を基にギブスブースト学習アルゴリズムによる学習処理を行なって最終仮説情報を作成する学習処理部と、判定対象のテキストデータからテキストデータに含まれる文章区間に対応する木構造を生成する第2木構造生成部と、この木構造と前記最終仮説情報とに基づき、文章区間が検索対象に該当するか否かを判定する判定処理部を備える。 |
| 実施実績 |
【無】 |
| 許諾実績 |
【無】 |
| 特許権譲渡 |
【否】
|
| 特許権実施許諾 |
【可】
|
)