| 出願番号 |
特願2008-061037 |
| 出願日 |
2008/3/11 |
| 出願人 |
日本放送協会 |
| 公開番号 |
特開2009-217006 |
| 公開日 |
2009/9/24 |
| 登録番号 |
特許第4990822号 |
| 特許権者 |
日本放送協会 |
| 発明の名称 |
辞書修正装置、システム、およびコンピュータプログラム |
| 技術分野 |
情報・通信 |
| 機能 |
機械・部品の製造、制御・ソフトウェア |
| 適用製品 |
辞書修正装置、音声認識システム、音声合成システム、およびコンピュータプログラム、放送番組の字幕制作、音声対話システム、会議議事録の音声認識による自動書き起こし |
| 目的 |
必要のない読みを自動的に判定して発音辞書から削除することで音声処理における正解率向上やサーチ時間短縮を目的とし、そのための辞書修正装置を提供する。 |
| 効果 |
学習データセットを元にした頻度データを用いて、必要性の低いエントリを削除した、また誤っている可能性のあるエントリを削除した、修正発音辞書データを得ることが可能となる。これにより、大語彙連続音声認識の正解率の向上や、認識の際の発音辞書データのサーチ時間の短縮や、また、音声合成の分野における高精度なテキスト解析処理が実現可能となり、音声処理分野全般において性能向上を図ることができる。 |
技術概要
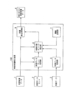 |
辞書修正装置が、第一閾値を記憶する閾値記憶部と、表記と、読みと、当該表記および当該読みが発生する頻度である発生頻度との組をエントリとして有する頻度データを読み込み、閾値記憶部から第一閾値を読み込み、発生頻度が第一閾値以上であるエントリが存在する表記に関して、その表記を有して且つ発生頻度が所定の第二閾値以下となるようなエントリを、削除対象エントリとして抽出する削除対象エントリ抽出部と、表記と読みとの組を有する発音辞書データから、削除対象エントリ抽出部によって抽出された削除対象エントリに対応するデータを削除して、修正発音辞書データを作成する辞書修正処理部を具備する。 |
| 実施実績 |
【無】 |
| 許諾実績 |
【無】 |
| 特許権譲渡 |
【否】
|
| 特許権実施許諾 |
【可】
|
)